Distributed Architecture ↗
noOriginal Documentation
Documentation Index#
Fetch the complete documentation index at: https://docs.trychroma.com/llms.txt Use this file to discover all available pages before exploring further.
How Chroma scales out with independent services, object storage, SSD caches, and a shared system database.
Distributed Chroma is designed for large-scale production workloads. Its components run as independent services so the system can scale horizontally while keeping a consistent API for clients.
Core Components#
Regardless of deployment mode, Chroma is composed of five core components. Each plays a distinct role in the system and operates over the shared Chroma data model.
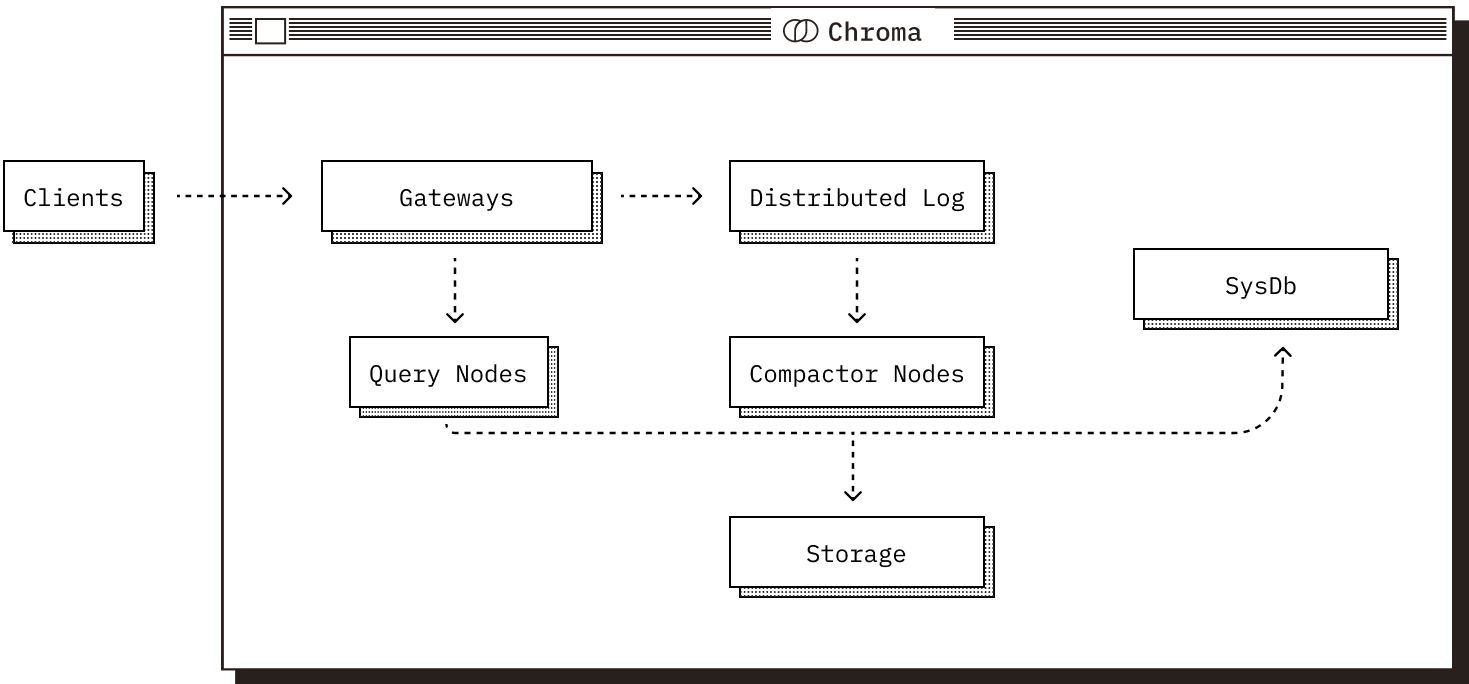
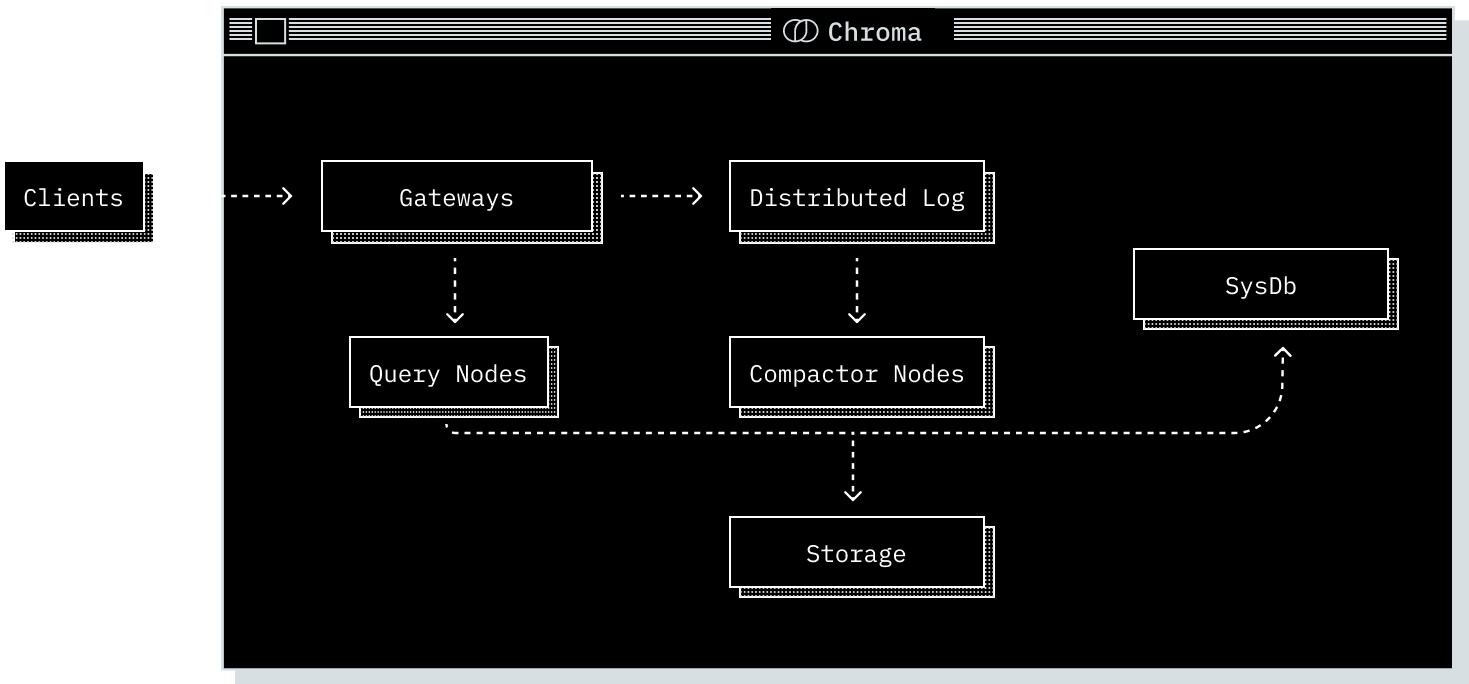
The Gateway#
The gateway is the entrypoint for client traffic.
- Exposes a consistent API across all deployment modes.
- Handles authentication, rate limiting, quota management, and request validation.
- Routes requests to downstream services.
The Log#
The log is Chroma’s write-ahead log.
- Records writes before they are acknowledged to clients.
- Ensures atomicity across multi-record writes.
- Provides durability and replay semantics.
The Query Executor#
The query executor is responsible for all read operations.
- Runs vector similarity, full-text, and metadata search.
- Maintains a mix of in-memory and on-disk indexes.
- Coordinates with the log to serve consistent results.
The Compactor#
The compactor periodically builds and maintains indexes.
- Reads from the log and produces updated vector, full-text, and metadata indexes.
- Writes materialized index data to storage.
- Updates the system database with metadata about new index versions.
The System Database#
The system database is Chroma’s internal catalog.
- Tracks tenants, databases, collections, and their metadata.
- Stores cluster metadata in distributed deployments.
- Is backed by a SQL database.
Runtime And Storage#
In distributed mode, Chroma’s components are deployed independently.
- The log and built indexes are stored in cloud object storage.
- The system catalog is backed by a SQL database.
- Services use local SSDs as caches to reduce object storage latency and cost.
This design separates compute from storage and lets Chroma scale collections and traffic without tying the whole system to a single machine.
Read Path#
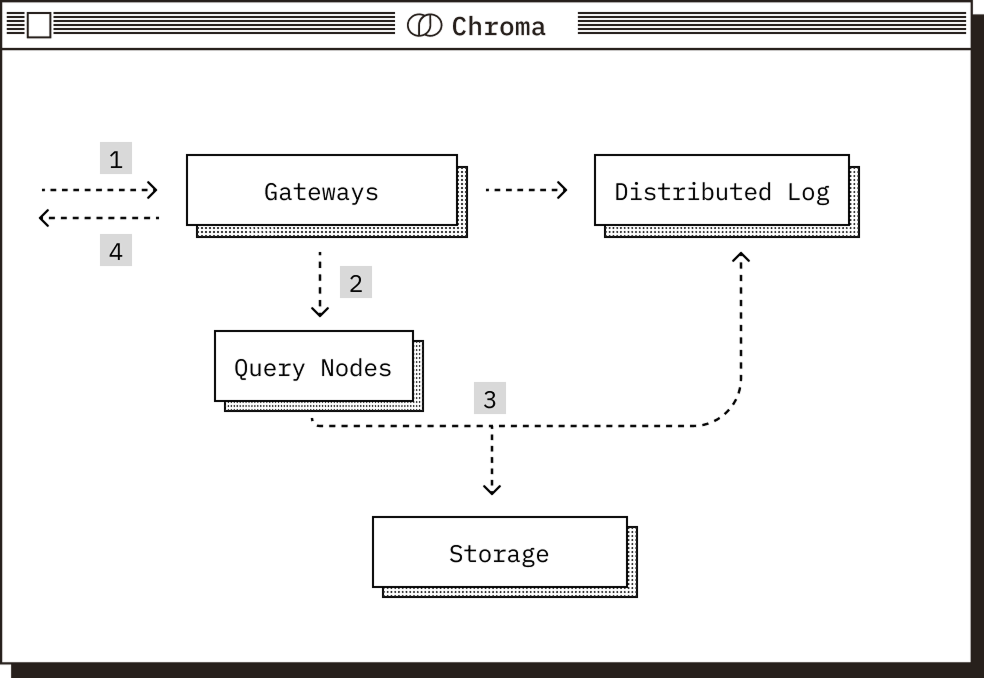
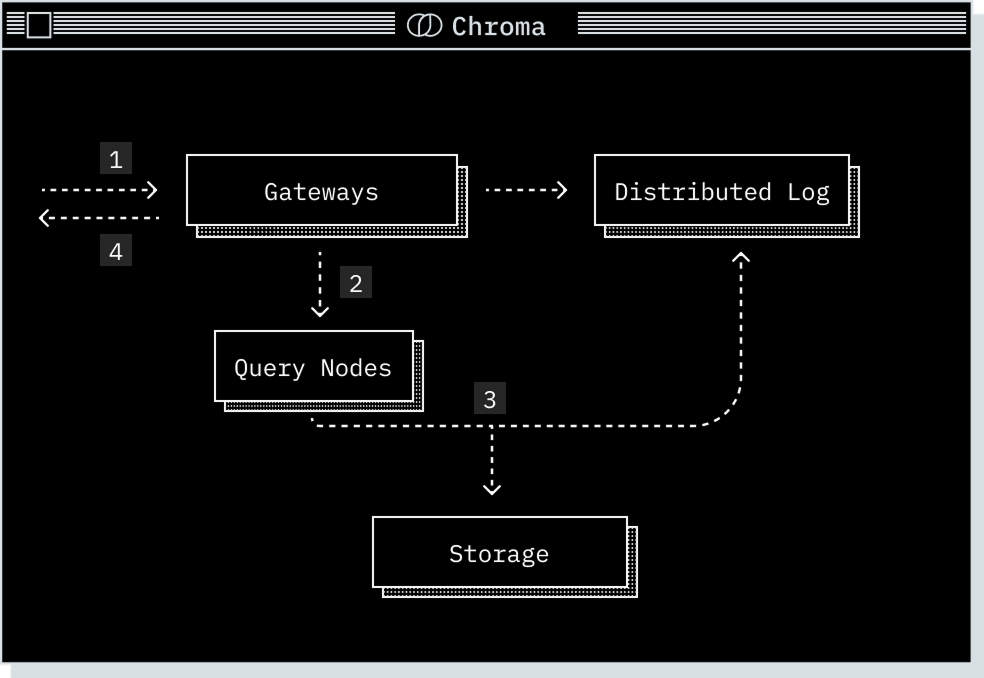
Write Path#
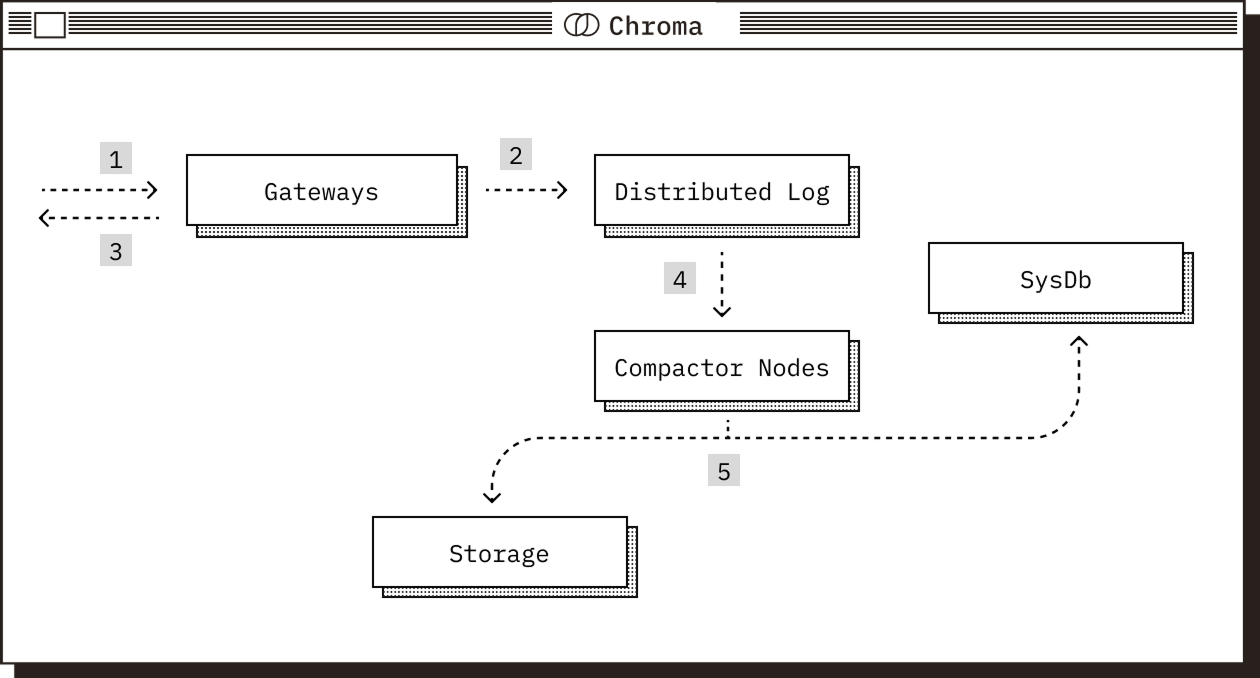
Tradeoffs#
Distributed Chroma is built on object storage to provide durable, low-cost storage at large scale. Object storage can deliver very high throughput, but it also introduces a higher baseline latency than local disk.
To reduce that latency penalty, Chroma aggressively uses SSD caching. When a collection is first queried, a subset of the required data is fetched from object storage, which can add cold-start latency. As the SSD cache warms, queries can be served from local cache instead of repeatedly hitting object storage.
Built with Mintlify.