Analyzing Hacker News with Cohere ↗
noOriginal Documentation
title: Analyzing Hacker News with Cohere slug: /page/analyzing-hacker-news description: >- This page describes building a generative-AI powered tool to analyze headlines with Cohere. image: type: fileId value: ‘https://files.buildwithfern.com/cohere.docs.buildwithfern.com/8ba30b46486ea7bfab24f3e8856d7411d1b745b26e9026abff3ee62af52ce268/assets/images/f1cc130-cohere_meta_image.jpg' keywords: ‘Cohere, analyzing text with a large language model.’#
{kind=link}
Large language models give machines a vastly improved representation and understanding of language. These abilities give developers more options for content recommendation, analysis, and filtering.
In this notebook we take thousands of the most popular posts from Hacker News and demonstrate some of these functionalities:
- Given an existing post title, retrieve the most similar posts (nearest neighbor search using embeddings)
- Given a query that we write, retrieve the most similar posts
- Plot the archive of articles by similarity (where similar posts are close together and different ones are far)
- Cluster the posts to identify the major common themes
- Extract major keywords from each cluster so we can identify what the clsuter is about
- (Experimental) Name clusters with a generative language model
Setup#
Let’s start by installing the tools we’ll need and then importing them.
!pip install cohere umap-learn altair annoy bertopicRequirement already satisfied: cohere in /Users/alexiscook/anaconda3/lib/python3.11/site-packages (5.1.5)
Requirement already satisfied: umap-learn in /Users/alexiscook/anaconda3/lib/python3.11/site-packages (0.5.5)
Requirement already satisfied: altair in /Users/alexiscook/anaconda3/lib/python3.11/site-packages (5.2.0)
Requirement already satisfied: annoy in /Users/alexiscook/anaconda3/lib/python3.11/site-packages (1.17.3)
Requirement already satisfied: bertopic in /Users/alexiscook/anaconda3/lib/python3.11/site-packages (0.16.0)
Requirement already satisfied: httpx>=0.21.2 in /Users/alexiscook/anaconda3/lib/python3.11/site-packages (from cohere) (0.27.0)
Requirement already satisfied: pydantic>=1.9.2 in /Users/alexiscook/anaconda3/lib/python3.11/site-packages (from cohere) (2.6.0)
Requirement already satisfied: typing_extensions>=4.0.0 in /Users/alexiscook/anaconda3/lib/python3.11/site-packages (from cohere) (4.10.0)
Requirement already satisfied: numpy>=1.17 in /Users/alexiscook/anaconda3/lib/python3.11/site-packages (from umap-learn) (1.24.3)
Requirement already satisfied: scipy>=1.3.1 in /Users/alexiscook/anaconda3/lib/python3.11/site-packages (from umap-learn) (1.11.1)
Requirement already satisfied: scikit-learn>=0.22 in /Users/alexiscook/anaconda3/lib/python3.11/site-packages (from umap-learn) (1.3.0)
Requirement already satisfied: numba>=0.51.2 in /Users/alexiscook/anaconda3/lib/python3.11/site-packages (from umap-learn) (0.57.0)
Requirement already satisfied: pynndescent>=0.5 in /Users/alexiscook/anaconda3/lib/python3.11/site-packages (from umap-learn) (0.5.12)
Requirement already satisfied: tqdm in /Users/alexiscook/anaconda3/lib/python3.11/site-packages (from umap-learn) (4.65.0)
Requirement already satisfied: jinja2 in /Users/alexiscook/anaconda3/lib/python3.11/site-packages (from altair) (3.1.2)
Requirement already satisfied: jsonschema>=3.0 in /Users/alexiscook/anaconda3/lib/python3.11/site-packages (from altair) (4.17.3)
Requirement already satisfied: packaging in /Users/alexiscook/anaconda3/lib/python3.11/site-packages (from altair) (23.2)
Requirement already satisfied: pandas>=0.25 in /Users/alexiscook/anaconda3/lib/python3.11/site-packages (from altair) (2.0.3)
Requirement already satisfied: toolz in /Users/alexiscook/anaconda3/lib/python3.11/site-packages (from altair) (0.12.0)
Requirement already satisfied: hdbscan>=0.8.29 in /Users/alexiscook/anaconda3/lib/python3.11/site-packages (from bertopic) (0.8.33)
Requirement already satisfied: sentence-transformers>=0.4.1 in /Users/alexiscook/anaconda3/lib/python3.11/site-packages (from bertopic) (2.6.1)
Requirement already satisfied: plotly>=4.7.0 in /Users/alexiscook/anaconda3/lib/python3.11/site-packages (from bertopic) (5.9.0)
Requirement already satisfied: cython<3,>=0.27 in /Users/alexiscook/anaconda3/lib/python3.11/site-packages (from hdbscan>=0.8.29->bertopic) (0.29.37)
Requirement already satisfied: joblib>=1.0 in /Users/alexiscook/anaconda3/lib/python3.11/site-packages (from hdbscan>=0.8.29->bertopic) (1.2.0)
Requirement already satisfied: anyio in /Users/alexiscook/anaconda3/lib/python3.11/site-packages (from httpx>=0.21.2->cohere) (3.5.0)
Requirement already satisfied: certifi in /Users/alexiscook/anaconda3/lib/python3.11/site-packages (from httpx>=0.21.2->cohere) (2023.11.17)
Requirement already satisfied: httpcore==1.* in /Users/alexiscook/anaconda3/lib/python3.11/site-packages (from httpx>=0.21.2->cohere) (1.0.2)
Requirement already satisfied: idna in /Users/alexiscook/anaconda3/lib/python3.11/site-packages (from httpx>=0.21.2->cohere) (3.4)
Requirement already satisfied: sniffio in /Users/alexiscook/anaconda3/lib/python3.11/site-packages (from httpx>=0.21.2->cohere) (1.2.0)
Requirement already satisfied: h11<0.15,>=0.13 in /Users/alexiscook/anaconda3/lib/python3.11/site-packages (from httpcore==1.*->httpx>=0.21.2->cohere) (0.14.0)
Requirement already satisfied: attrs>=17.4.0 in /Users/alexiscook/anaconda3/lib/python3.11/site-packages (from jsonschema>=3.0->altair) (22.1.0)
Requirement already satisfied: pyrsistent!=0.17.0,!=0.17.1,!=0.17.2,>=0.14.0 in /Users/alexiscook/anaconda3/lib/python3.11/site-packages (from jsonschema>=3.0->altair) (0.18.0)
Requirement already satisfied: llvmlite<0.41,>=0.40.0dev0 in /Users/alexiscook/anaconda3/lib/python3.11/site-packages (from numba>=0.51.2->umap-learn) (0.40.0)
Requirement already satisfied: python-dateutil>=2.8.2 in /Users/alexiscook/anaconda3/lib/python3.11/site-packages (from pandas>=0.25->altair) (2.8.2)
Requirement already satisfied: pytz>=2020.1 in /Users/alexiscook/anaconda3/lib/python3.11/site-packages (from pandas>=0.25->altair) (2023.3.post1)
Requirement already satisfied: tzdata>=2022.1 in /Users/alexiscook/anaconda3/lib/python3.11/site-packages (from pandas>=0.25->altair) (2023.3)
Requirement already satisfied: tenacity>=6.2.0 in /Users/alexiscook/anaconda3/lib/python3.11/site-packages (from plotly>=4.7.0->bertopic) (8.2.2)
Requirement already satisfied: annotated-types>=0.4.0 in /Users/alexiscook/anaconda3/lib/python3.11/site-packages (from pydantic>=1.9.2->cohere) (0.6.0)
Requirement already satisfied: pydantic-core==2.16.1 in /Users/alexiscook/anaconda3/lib/python3.11/site-packages (from pydantic>=1.9.2->cohere) (2.16.1)
Requirement already satisfied: threadpoolctl>=2.0.0 in /Users/alexiscook/anaconda3/lib/python3.11/site-packages (from scikit-learn>=0.22->umap-learn) (2.2.0)
Requirement already satisfied: transformers<5.0.0,>=4.32.0 in /Users/alexiscook/anaconda3/lib/python3.11/site-packages (from sentence-transformers>=0.4.1->bertopic) (4.39.3)
Requirement already satisfied: torch>=1.11.0 in /Users/alexiscook/anaconda3/lib/python3.11/site-packages (from sentence-transformers>=0.4.1->bertopic) (2.2.2)
Requirement already satisfied: huggingface-hub>=0.15.1 in /Users/alexiscook/anaconda3/lib/python3.11/site-packages (from sentence-transformers>=0.4.1->bertopic) (0.22.2)
Requirement already satisfied: Pillow in /Users/alexiscook/anaconda3/lib/python3.11/site-packages (from sentence-transformers>=0.4.1->bertopic) (10.0.1)
Requirement already satisfied: MarkupSafe>=2.0 in /Users/alexiscook/anaconda3/lib/python3.11/site-packages (from jinja2->altair) (2.1.1)
Requirement already satisfied: filelock in /Users/alexiscook/anaconda3/lib/python3.11/site-packages (from huggingface-hub>=0.15.1->sentence-transformers>=0.4.1->bertopic) (3.9.0)
Requirement already satisfied: fsspec>=2023.5.0 in /Users/alexiscook/anaconda3/lib/python3.11/site-packages (from huggingface-hub>=0.15.1->sentence-transformers>=0.4.1->bertopic) (2024.3.1)
Requirement already satisfied: pyyaml>=5.1 in /Users/alexiscook/anaconda3/lib/python3.11/site-packages (from huggingface-hub>=0.15.1->sentence-transformers>=0.4.1->bertopic) (6.0)
Requirement already satisfied: requests in /Users/alexiscook/anaconda3/lib/python3.11/site-packages (from huggingface-hub>=0.15.1->sentence-transformers>=0.4.1->bertopic) (2.31.0)
Requirement already satisfied: six>=1.5 in /Users/alexiscook/anaconda3/lib/python3.11/site-packages (from python-dateutil>=2.8.2->pandas>=0.25->altair) (1.16.0)
Requirement already satisfied: sympy in /Users/alexiscook/anaconda3/lib/python3.11/site-packages (from torch>=1.11.0->sentence-transformers>=0.4.1->bertopic) (1.11.1)
Requirement already satisfied: networkx in /Users/alexiscook/anaconda3/lib/python3.11/site-packages (from torch>=1.11.0->sentence-transformers>=0.4.1->bertopic) (3.1)
Requirement already satisfied: regex!=2019.12.17 in /Users/alexiscook/anaconda3/lib/python3.11/site-packages (from transformers<5.0.0,>=4.32.0->sentence-transformers>=0.4.1->bertopic) (2022.7.9)
Requirement already satisfied: tokenizers<0.19,>=0.14 in /Users/alexiscook/anaconda3/lib/python3.11/site-packages (from transformers<5.0.0,>=4.32.0->sentence-transformers>=0.4.1->bertopic) (0.15.2)
Requirement already satisfied: safetensors>=0.4.1 in /Users/alexiscook/anaconda3/lib/python3.11/site-packages (from transformers<5.0.0,>=4.32.0->sentence-transformers>=0.4.1->bertopic) (0.4.2)
Requirement already satisfied: charset-normalizer<4,>=2 in /Users/alexiscook/anaconda3/lib/python3.11/site-packages (from requests->huggingface-hub>=0.15.1->sentence-transformers>=0.4.1->bertopic) (3.3.2)
Requirement already satisfied: urllib3<3,>=1.21.1 in /Users/alexiscook/anaconda3/lib/python3.11/site-packages (from requests->huggingface-hub>=0.15.1->sentence-transformers>=0.4.1->bertopic) (1.26.18)
Requirement already satisfied: mpmath>=0.19 in /Users/alexiscook/anaconda3/lib/python3.11/site-packages (from sympy->torch>=1.11.0->sentence-transformers>=0.4.1->bertopic) (1.3.0)import cohere
import numpy as np
import pandas as pd
import umap
import altair as alt
from annoy import AnnoyIndex
import warnings
from sklearn.cluster import KMeans
from sklearn.feature_extraction.text import CountVectorizer
from bertopic.vectorizers import ClassTfidfTransformer
warnings.filterwarnings('ignore')
pd.set_option('display.max_colwidth', None)Fill in your Cohere API key in the next cell. To do this, begin by signing up to Cohere (for free!) if you haven’t yet. Then get your API key here.
co = cohere.Client("COHERE_API_KEY") # Insert your Cohere API keyDataset: Top 3,000 Ask HN posts#
We will use the top 3,000 posts from the Ask HN section of Hacker News. We provide a CSV containing the posts.
df = pd.read_csv('https://storage.googleapis.com/cohere-assets/blog/text-clustering/data/askhn3k_df.csv', index_col=0)
print(f'Loaded a DataFrame with {len(df)} rows')Loaded a DataFrame with 3000 rowsdf.head() |
|---|
| 0 |
| 1 |
| 2 |
| 3 |
| 4 |
We calculate the embeddings using Cohere’s embed-v4.0 model. The resulting embeddings matrix has 3,000 rows (one for each post) and 1024 columns (meaning each post title is represented with a 1024-dimensional embedding).
batch_size = 90
embeds_list = []
for i in range(0, len(df), batch_size):
batch = df[i : min(i + batch_size, len(df))]
texts = list(batch["title"])
embs_batch = co.embed(
texts=texts, model="embed-v4.0", input_type="search_document"
).embeddings
embeds_list.extend(embs_batch)
embeds = np.array(embeds_list)
embeds.shape(3000, 1024)Building a semantic search index#
For nearest-neighbor search, we can use the open-source Annoy library. Let’s create a semantic search index and feed it all the embeddings.
search_index = AnnoyIndex(embeds.shape[1], 'angular')
for i in range(len(embeds)):
search_index.add_item(i, embeds[i])
search_index.build(10) # 10 trees
search_index.save('askhn.ann')True1- Given an existing post title, retrieve the most similar posts (nearest neighbor search using embeddings)#
We can query neighbors of a specific post using get_nns_by_item.
example_id = 50
similar_item_ids = search_index.get_nns_by_item(example_id,
10, # Number of results to retrieve
include_distances=True)
results = pd.DataFrame(data={'post titles': df.iloc[similar_item_ids[0]]['title'],
'distance': similar_item_ids[1]}).drop(example_id)
print(f"Query post:'{df.iloc[example_id]['title']}'\nNearest neighbors:")
resultsQuery post:'Pick startups for YC to fund'
Nearest neighbors: |
|---|
| 2991 |
| 2910 |
| 31 |
| 685 |
| 2123 |
| 727 |
| 2972 |
| 2589 |
| 2708 |
2- Given a query that we write, retrieve the most similar posts#
We’re not limited to searching using existing items. If we get a query, we can embed it and find its nearest neighbors from the dataset.
query = "How can I improve my knowledge of calculus?"
query_embed = co.embed(texts=[query],
model="embed-v4.0",
truncate="RIGHT",
input_type="search_query").embeddings
similar_item_ids = search_index.get_nns_by_vector(query_embed[0], 10, include_distances=True)
results = pd.DataFrame(data={'texts': df.iloc[similar_item_ids[0]]['title'],
'distance': similar_item_ids[1]})
print(f"Query:'{query}'\nNearest neighbors:")
resultsQuery:'How can I improve my knowledge of calculus?'
Nearest neighbors: |
|---|
| 2457 |
| 1235 |
| 145 |
| 1317 |
| 910 |
| 2432 |
| 1994 |
| 1529 |
| 796 |
| 1286 |
3- Plot the archive of articles by similarity#
What if we want to browse the archive instead of only searching it? Let’s plot all the questions in a 2D chart so you’re able to visualize the posts in the archive and their similarities.
reducer = umap.UMAP(n_neighbors=100)
umap_embeds = reducer.fit_transform(embeds)df['x'] = umap_embeds[:,0]
df['y'] = umap_embeds[:,1]
chart = alt.Chart(df).mark_circle(size=60).encode(
x=#'x',
alt.X('x',
scale=alt.Scale(zero=False),
axis=alt.Axis(labels=False, ticks=False, domain=False)
),
y=
alt.Y('y',
scale=alt.Scale(zero=False),
axis=alt.Axis(labels=False, ticks=False, domain=False)
),
tooltip=['title']
).configure(background="#FDF7F0"
).properties(
width=700,
height=400,
title='Ask HN: top 3,000 posts'
)
chart.interactive()4- Cluster the posts to identify the major common themes#
Let’s proceed to cluster the embeddings using KMeans from scikit-learn.
n_clusters = 8
kmeans_model = KMeans(n_clusters=n_clusters, random_state=0)
classes = kmeans_model.fit_predict(embeds)5- Extract major keywords from each cluster so we can identify what the cluster is about#
documents = df['title']
documents = pd.DataFrame({"Document": documents,
"ID": range(len(documents)),
"Topic": None})
documents['Topic'] = classes
documents_per_topic = documents.groupby(['Topic'], as_index=False).agg({'Document': ' '.join})
count_vectorizer = CountVectorizer(stop_words="english").fit(documents_per_topic.Document)
count = count_vectorizer.transform(documents_per_topic.Document)
words = count_vectorizer.get_feature_names_out()ctfidf = ClassTfidfTransformer().fit_transform(count).toarray()
words_per_class = {label: [words[index] for index in ctfidf[label].argsort()[-10:]] for label in documents_per_topic.Topic}
df['cluster'] = classes
df['keywords'] = df['cluster'].map(lambda topic_num: ", ".join(np.array(words_per_class[topic_num])[:]))Plot with clusters and keywords information#
We can now plot the documents with their clusters and keywords
selection = alt.selection_multi(fields=['keywords'], bind='legend')
chart = alt.Chart(df).transform_calculate(
url='https://news.ycombinator.com/item?id=' + alt.datum.id
).mark_circle(size=60, stroke='#666', strokeWidth=1, opacity=0.3).encode(
x=#'x',
alt.X('x',
scale=alt.Scale(zero=False),
axis=alt.Axis(labels=False, ticks=False, domain=False)
),
y=
alt.Y('y',
scale=alt.Scale(zero=False),
axis=alt.Axis(labels=False, ticks=False, domain=False)
),
href='url:N',
color=alt.Color('keywords:N',
legend=alt.Legend(columns=1, symbolLimit=0, labelFontSize=14)
),
opacity=alt.condition(selection, alt.value(1), alt.value(0.2)),
tooltip=['title', 'keywords', 'cluster', 'score', 'descendants']
).properties(
width=800,
height=500
).add_selection(
selection
).configure_legend(labelLimit= 0).configure_view(
strokeWidth=0
).configure(background="#FDF7F0").properties(
title='Ask HN: Top 3,000 Posts'
)
chart.interactive()6- (Experimental) Naming clusters with a generative language model#
While the extracted keywords do add a lot of information to help us identify the clusters at a glance, we should be able to have a generative model look at these keywords and suggest a name. So far I have reasonable results from a prompt that looks like this:
The common theme of the following words: books, book, read, the, you, are, what, best, in, your
is that they all relate to favorite books to read.
---
The common theme of the following words: startup, company, yc, failed
is that they all relate to startup companies and their failures.
---
The common theme of the following words: freelancer, wants, hired, be, who, seeking, to, 2014, 2020, april
is that they all relate to hiring for a freelancer to join the team of a startup.
---
The common theme of the following words: <insert keywords here>
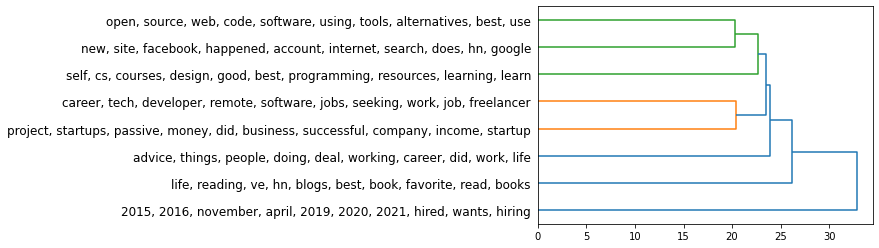
is that they all relate toThere’s a lot of room for improvement though. I’m really excited by this use case because it adds so much information. Imagine if the in the following tree of topics, you assigned each cluster an intelligible name. Then imagine if you assigned each branching a name as well
We can’t wait to see what you start building! Share your projects or find support on our Discord server.