Managed Fine-Tuning Overview ↗
noOriginal Documentation
Documentation Index#
Fetch the complete documentation index at: https://docs.fireworks.ai/llms.txt Use this file to discover all available pages before exploring further.
Fine-tune models with Fireworks-managed infrastructure — no custom code required.
Give Fireworks your data and configuration. The platform handles scheduling, training, checkpointing, and model output. Training data uses the OpenAI-compatible chat completion format, so existing OpenAI SFT datasets work with no conversion required.
Methods#
Train text models with labeled examples of desired outputs
Train vision-language models with image and text pairs
Align models with human preferences using pairwise comparisons
Train models using custom reward functions for complex reasoning tasks
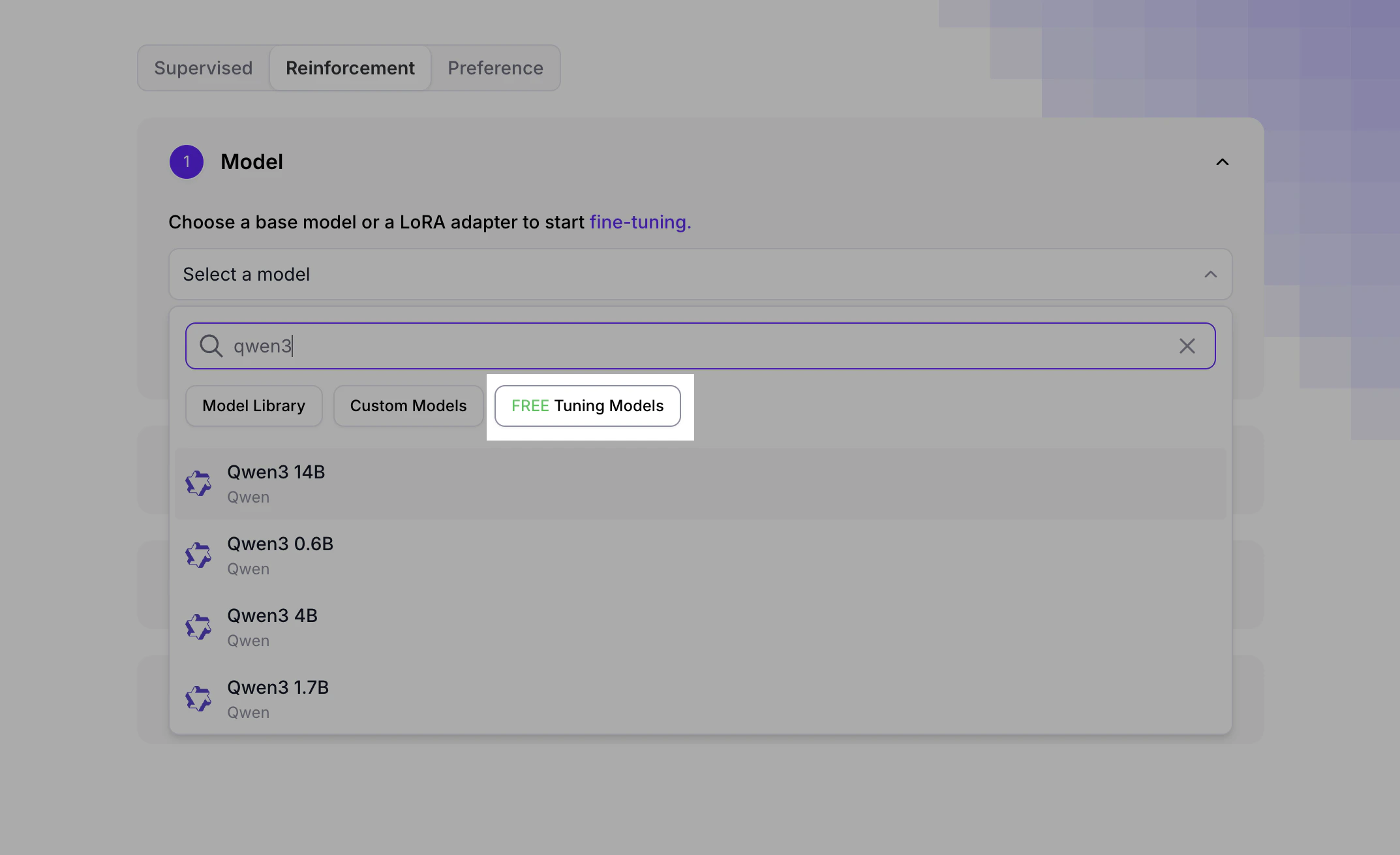
Free Reinforcement Fine-Tuning#
Reinforcement Fine-Tuning (RFT) is free for models under 16B parameters. When creating an RFT job in the UI, filter for free tuning models in the model selection area on the fine-tuning creation page. If kicking off jobs from the terminal, you can find the model ID from the Model Library. Note: SFT and DPO jobs are billed per training token for all model sizes—see the pricing page for details.
When creating a Reinforcement Fine-Tuning job in the UI, look for the “Free tuning” filter in the model selection area:
For SFT and DPO pricing, see the pricing page.
Supported base models#
Fireworks supports fine-tuning for most major open source models, including DeepSeek, Qwen, Kimi, Gemma, GLM, and Llama families. The same set of base models is available for SFT, DPO, and RFT — once a base model is supported, every managed fine-tuning method works against it.
The table below is generated from the live training shape registry. The “Max supported context length” is the largest max_supported_context_length across all training shapes registered for that base model — use it as the upper bound when you set a per-job context length on firectl sftj create, firectl dpoj create, or RFT job creation.
| Base model | Max supported context length |
|---|---|
gemma-4-26b-a4b-it | 256K (262,144 tokens) |
gemma-4-31b-it | 256K (262,144 tokens) |
glm-5p1 | 200K (200,000 tokens) |
kimi-k2p5 | 256K (262,144 tokens) |
kimi-k2p6 | 256K (262,144 tokens) |
llama-v3p3-70b-instruct | 128K (131,072 tokens) |
minimax-m2p5 | 192K (196,608 tokens) |
nemotron-nano-3-30b-a3b | 256K (262,144 tokens) |
qwen3-235b-a22b-instruct-2507 | 128K (128,000 tokens) |
qwen3-30b-a3b | 128K (131,072 tokens) |
qwen3-30b-a3b-instruct-2507 | 128K (128,000 tokens) |
qwen3-32b | 128K (131,072 tokens) |
qwen3-4b | 64K (65,536 tokens) |
qwen3-8b | 256K (256,000 tokens) |
qwen3-vl-8b-instruct | 256K (262,144 tokens) |
qwen3p5-27b | 256K (262,144 tokens) |
qwen3p5-35b-a3b | 256K (262,144 tokens) |
qwen3p5-397b-a17b | 256K (262,144 tokens) |
qwen3p5-9b | 256K (262,144 tokens) |
qwen3p6-27b | 256K (262,144 tokens) |
To browse the broader catalog (including non-tunable inference models), visit the Model Library for text models or vision models.
Tuning modes and context length#
Managed fine-tuning supports both Low-Rank Adaptation (LoRA) and full-parameter tuning, depending on the model, method, and selected training shape. It also supports the full context lengths exposed by the available training shapes, matching the same long-context capabilities used by cookbook recipes.
Choose LoRA when you want efficient adapter training and flexible deployment, including multiple LoRAs on a single base model deployment. Choose full-parameter tuning when you need to update all model weights for difficult reasoning, alignment, or domain adaptation tasks.
Deprecation notice: The deployedModel request key for routing to LoRA addons is deprecated and will not be supported for any new deployments. Please migrate to the model field with the <model_name>#<deployment_name> format described in Routing requests to LoRA addons.