Log LLM calls ↗
noOriginal Documentation
Documentation Index#
Fetch the complete documentation index at: https://docs.langchain.com/llms.txt Use this file to discover all available pages before exploring further.
This guide will cover how to log LLM calls to LangSmith when you are using a custom model or a custom input/output format. To make the most of LangSmith’s LLM trace processing, you should log your LLM traces in one of the specified formats.
LangSmith offers the following benefits for LLM traces:
- Rich, structured rendering of message lists
- Token and cost tracking per LLM call, per trace and across traces over time
If you don’t log your LLM traces in the suggested formats, you will still be able to log the data to LangSmith, but it may not be processed or rendered in expected ways.
If you are using LangChain OSS to call language models or LangSmith wrappers (OpenAI, Anthropic), these approaches will automatically log traces in the correct format.
The examples on this page use the traceable decorator/wrapper to log the model run (which is the recommended approach for Python and JS/TS). However, the same idea applies if you are using the RunTree or API directly.
Messages format#
When tracing a custom model or a custom input/output format, it must either follow the LangChain format, OpenAI completions format or Anthropic messages format. For more details, refer to the OpenAI Chat Completions or Anthropic Messages documentation. The LangChain format is:
system | reasoning | user | assistant | tool
<ParamField path="type" type="string" required>
One of: <code>text</code> | <code>image</code> | <code>file</code> | <code>audio</code> | <code>video</code> | <code>tool\_call</code> | <code>server\_tool\_call</code> | <code>server\_tool\_result</code>.
</ParamField>
<ParamField path="type" type="literal('text')" required />
<ParamField path="text" type="string" required>
Text content.
</ParamField>
<ParamField path="annotations" type="object[]">
List of annotations for the text
</ParamField>
<ParamField path="extras" type="object">
Additional provider-specific data.
</ParamField>
<ParamField path="type" type="literal('reasoning')" required />
<ParamField path="text" type="string" required>
Text content.
</ParamField>
<ParamField path="extras" type="object">
Additional provider-specific data.
</ParamField>
<ParamField path="type" type="literal('image')" required />
<ParamField path="url" type="string">
URL pointing to the image location.
</ParamField>
<ParamField path="base64" type="string" required>
Base64-encoded image data.
</ParamField>
<ParamField path="id" type="string">
Reference ID to an externally stored image (e.g., in a provider’s file system or in a bucket).
</ParamField>
<ParamField path="mime_type" type="string">
Image [MIME type](https://www.iana.org/assignments/media-types/media-types.xhtml#image) (e.g., `image/jpeg`, `image/png`).
</ParamField>
<ParamField path="type" type="literal('file')" required />
<ParamField path="url" type="string">
URL pointing to the file.
</ParamField>
<ParamField path="base64" type="string" required>
Base64-encoded file data.
</ParamField>
<ParamField path="id" type="string">
Reference ID to an externally stored file (e.g., in a provider’s file system or in a bucket).
</ParamField>
<ParamField path="mime_type" type="string">
File [MIME type](https://www.iana.org/assignments/media-types/media-types.xhtml#image) (e.g., `application/pdf`).
</ParamField>
<ParamField path="type" type="literal('audio')" required />
<ParamField path="url" type="string">
URL pointing to the audio file.
</ParamField>
<ParamField path="base64" type="string" required>
Base64-encoded audio data.
</ParamField>
<ParamField path="id" type="string">
Reference ID to an externally stored audio file (e.g., in a provider’s file system or in a bucket).
</ParamField>
<ParamField path="mime_type" type="string">
Audio [MIME type](https://www.iana.org/assignments/media-types/media-types.xhtml#image) (e.g., `audio/mpeg`, `audio/wav`).
</ParamField>
<ParamField path="type" type="literal('video')" required />
<ParamField path="url" type="string">
URL pointing to the video file.
</ParamField>
<ParamField path="base64" type="string" required>
Base64-encoded video data.
</ParamField>
<ParamField path="id" type="string">
Reference ID to an externally stored video file (e.g., in a provider’s file system or in a bucket).
</ParamField>
<ParamField path="mime_type" type="string">
Video [MIME type](https://www.iana.org/assignments/media-types/media-types.xhtml#image) (e.g., `video/mp4`, `video/webm`).
</ParamField>
<ParamField path="type" type="literal('tool_call')" required />
<ParamField path="name" type="string" />
<ParamField path="args" type="object" required>
Arguments to pass to the tool.
</ParamField>
<ParamField path="id" type="string">
Unique identifier for this tool call.
</ParamField>
<ParamField path="type" type="literal('server_tool_call')" required />
<ParamField path="id" type="string" required>
Unique identifier for this tool call.
</ParamField>
<ParamField path="name" type="string" required>
The name of the tool to be called.
</ParamField>
<ParamField path="args" type="object" required>
Arguments to pass to the tool.
</ParamField>
<ParamField path="type" type="literal('server_tool_result')" required />
<ParamField path="tool_call_id" type="string" required>
Identifier of the corresponding server tool call.
</ParamField>
<ParamField path="id" type="string">
Unique identifier for this tool call.
</ParamField>
<ParamField path="status" type="string" required>
Execution status of the server-side tool. One of: <code>success</code> | <code>error</code>.
</ParamField>
<ParamField path="output">
Output of the executed tool.
</ParamField>
id of a prior assistant message’s tool\_calls\[i] entry. Only valid when role is tool.
Examples#
inputs = {
"messages": [
{
"role": "user",
"content": [
{
"type": "text",
"text": "Hi, can you tell me the capital of France?"
}
]
}
]
}
outputs = {
"messages": [
{
"role": "assistant",
"content": [
{
"type": "text",
"text": "The capital of France is Paris."
},
{
"type": "reasoning",
"text": "The user is asking about..."
}
]
}
]
}input = {
"messages": [
{
"role": "user",
"content": [
{
"type": "text",
"text": "What's the weather in San Francisco?"
}
]
}
]
}
outputs = {
"messages": [
{
"role": "assistant",
"content": [{"type": "tool_call", "name": "get_weather", "args": {"city": "San Francisco"}, "id": "call_1"}],
},
{
"role": "tool",
"tool_call_id": "call_1",
"content": [
{
"type": "text",
"text": "{\"temperature\": \"18°C\", \"condition\": \"Sunny\"}"
}
]
},
{
"role": "assistant",
"content": [
{
"type": "text",
"text": "The weather in San Francisco is 18°C and sunny."
}
]
}
]
}inputs = {
"messages": [
{
"role": "user",
"content": [
{
"type": "text",
"text": "What breed is this dog?"
},
{
"type": "image",
"url": "https://fastly.picsum.photos/id/237/200/300.jpg?hmac=TmmQSbShHz9CdQm0NkEjx1Dyh_Y984R9LpNrpvH2D_U",
# alternative to a url, you can provide a base64 encoded image
# "base64": "<base64 encoded image>",
"mime_type": "image/jpeg",
}
]
}
]
}
outputs = {
"messages": [
{
"role": "assistant",
"content": [
{
"type": "text",
"text": "This looks like a Black Labrador."
}
]
}
]
}input = {
"messages": [
{
"role": "user",
"content": [
{
"type": "text",
"text": "What is the price of AAPL?"
}
]
}
]
}
output = {
"messages": [
{
"role": "assistant",
"content": [
{
"type": "server_tool_call",
"name": "web_search",
"args": {
"query": "price of AAPL",
"type": "search"
},
"id": "call_1"
},
{
"type": "server_tool_result",
"tool_call_id": "call_1",
"status": "success"
},
{
"type": "text",
"text": "The price of AAPL is $150.00"
}
]
}
]
}Converting custom I/O formats into LangSmith compatible formats#
If you’re using a custom input or output format, you can convert it to a LangSmith compatible format using process_inputs/processInputs and process_outputs/processOutputs functions on the @traceable decorator (Python) or traceable function (TS).
process_inputs/processInputs and process_outputs/processOutputs accept functions that allow you to transform the inputs and outputs of a specific trace before they are logged to LangSmith. They have access to the trace’s inputs and outputs, and can return a new dictionary with the processed data.
Here’s a boilerplate example of how to use process_inputs and process_outputs to convert a custom I/O format into a LangSmith compatible format:
class OriginalInputs(BaseModel):
"""Your app's custom request shape"""
class OriginalOutputs(BaseModel):
"""Your app's custom response shape."""
class LangSmithInputs(BaseModel):
"""The input format LangSmith expects."""
class LangSmithOutputs(BaseModel):
"""The output format LangSmith expects."""
def process_inputs(inputs: dict) -> dict:
"""Dict -> OriginalInputs -> LangSmithInputs -> dict"""
def process_outputs(output: Any) -> dict:
"""OriginalOutputs -> LangSmithOutputs -> dict"""
@traceable(run_type="llm", process_inputs=process_inputs, process_outputs=process_outputs)
def chat_model(inputs: dict) -> dict:
"""
Your app's model call. Keeps your custom I/O shape.
The decorators call process_* to log LangSmith-compatible format.
"""
```
## Identifying a custom model in traces
When using a custom model, it is recommended to also provide the following `metadata` fields to identify the model when viewing traces and when filtering.
* `ls_provider`: The provider of the model, e.g. "openai", "anthropic", etc.
* `ls_model_name`: The name of the model, e.g. "gpt-4.1-mini", "claude-3-opus-20240229", etc.
```python
from langsmith import traceable
inputs = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "I'd like to book a table for two."},
]
output = {
"choices": [
{
"message": {
"role": "assistant",
"content": "Sure, what time would you like to book the table for?"
}
}
]
}
@traceable(
run_type="llm",
metadata={"ls_provider": "my_provider", "ls_model_name": "my_model"}
)
def chat_model(messages: list):
return output
chat_model(inputs)import { traceable } from "langsmith/traceable";
const messages = [
{ role: "system", content: "You are a helpful assistant." },
{ role: "user", content: "I'd like to book a table for two." }
];
const output = {
choices: [
{
message: {
role: "assistant",
content: "Sure, what time would you like to book the table for?",
},
},
],
usage_metadata: {
input_tokens: 27,
output_tokens: 13,
total_tokens: 40,
},
};
// Can also use one of:
// const output = {
// message: {
// role: "assistant",
// content: "Sure, what time would you like to book the table for?"
// }
// };
//
// const output = {
// role: "assistant",
// content: "Sure, what time would you like to book the table for?"
// };
//
// const output = ["assistant", "Sure, what time would you like to book the table for?"];
const chatModel = traceable(
async ({ messages }: { messages: { role: string; content: string }[] }) => {
return output;
},
{
run_type: "llm",
name: "chat_model",
metadata: {
ls_provider: "my_provider",
ls_model_name: "my_model"
}
}
);
await chatModel({ messages });This code will log the following trace:
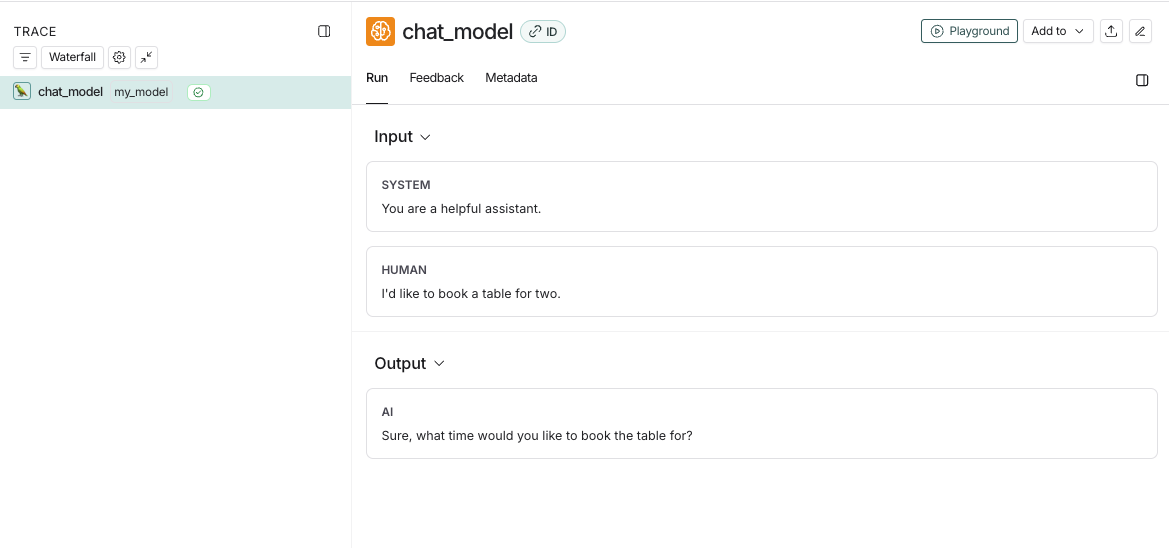
If you implement a custom streaming chat_model, you can “reduce” the outputs into the same format as the non-streaming version. This is currently only supported in Python.
def _reduce_chunks(chunks: list):
all_text = "".join([chunk["choices"][0]["message"]["content"] for chunk in chunks])
return {"choices": [{"message": {"content": all_text, "role": "assistant"}}]}
@traceable(
run_type="llm",
reduce_fn=_reduce_chunks,
metadata={"ls_provider": "my_provider", "ls_model_name": "my_model"}
)
def my_streaming_chat_model(messages: list):
for chunk in ["Hello, " + messages[1]["content"]]:
yield {
"choices": [
{
"message": {
"content": chunk,
"role": "assistant",
}
}
]
}
list(
my_streaming_chat_model(
[
{"role": "system", "content": "You are a helpful assistant. Please greet the user."},
{"role": "user", "content": "polly the parrot"},
],
)
)
If ls_model_name is not present in extra.metadata, other fields might be used from the extra.metadata for estimating token counts. The following fields are used in the order of precedence:
metadata.ls_model_nameinputs.modelinputs.model_name
To learn more about how to use the metadata fields, refer to the Add metadata and tags guide.
Provide token and cost information#
LangSmith calculates costs derived from token counts and model prices automatically. Learn about how to provide tokens and/or costs in a run and viewing costs in the LangSmith UI.
Time-to-first-token#
If you are using traceable or one of our SDK wrappers, LangSmith will automatically populate time-to-first-token for streaming LLM runs.
However, if you are using the RunTree API directly, you will need to add a new_token event to the run tree in order to properly populate time-to-first-token.
Here’s an example:
from langsmith.run_trees import RunTree
run_tree = RunTree(
name="CustomChatModel",
run_type="llm",
inputs={ ... }
)
run_tree.post()
llm_stream = ...
first_token = None
for token in llm_stream:
if first_token is None:
first_token = token
run_tree.add_event({
"name": "new_token"
})
run_tree.end(outputs={ ... })
run_tree.patch()import { RunTree } from "langsmith";
const runTree = new RunTree({
name: "CustomChatModel",
run_type: "llm",
inputs: { ... },
});
await runTree.postRun();
const llmStream = ...;
let firstToken;
for (const token of llmStream) {
if (firstToken == null) {
firstToken = token;
runTree.addEvent({ name: "new_token" });
}
}
await runTree.end({
outputs: { ... },
});
await runTree.patchRun();Edit this page on GitHub or file an issue.
Connect these docs to Claude, VSCode, and more via MCP for real-time answers.